Vision + ONNX + admit
Tiny shared package for loading MediaPipe and onnxruntime-web, fetching the vocabulary, and the pure admitToken function used by the production mode controller.
The Signchat pipeline is seven stages, three packages, and zero relay servers. Camera frames stay on the device; tokens and audio go directly from the browser to OpenRouter and ElevenLabs. Target: sign-end to first audible byte at p50 ~0.6 s, p95 ~0.9 s.
Each stage is a small file you can read in one sitting. The whole turn fits inside a single browser tab — there is no Signchat backend on the per-turn path.
The signer's webcam stream is sent to MediaPipe Tasks Vision (face, gesture, pose) and reduced to per-frame landmarks. Loaders live in the small @signchat/sign-pipeline package; the per-frame runner is in @signchat/runtime-browser.
A 48-frame ring of landmarks is fed into the ONNX classifier every ~500 ms. Softmax over 250 classes; two known-noisy labels are zeroed; the top-3 are emitted as ClassifierResults.
Recognized labels only enter the SignBuffer if they're either consistently top-1 across STABILITY_TICKS ticks (stable) or top-1 with a credible top-2 contender (band). This is the dropout filter against jittery single-tick predictions.
When the signer pauses, the buffered tokens plus recent hearing captions become a structured prompt. The browser POSTs directly to OpenRouter — no Vercel relay — with a JSON-schema response format constraining the model to { sentence, confidence, … }.
The model's response is parsed and validated against a Zod schema. Any malformed payload throws a ReconstructionParseError — there's no "fallback voice"; an error stays loud so the signer knows the turn failed.
The reconstructed sentence enters the mode controller's preview state. In auto mode it advances to speaking after a configurable silence; in proofread mode the signer must explicitly Approve, Edit, Re-sign, or Discard.
The approved sentence is streamed sentence-at-a-time to ElevenLabs Flash v2.5 over a WebSocket. Returned 24 kHz PCM is decoded and mixed with the user's mic in Web Audio and published as a single LiveKit signchat-voice track that the hearing peer subscribes to like any other call audio.
The pipeline is split across three workspace packages so the heavy bits (network, audio, FSM) can be reused by the Bridge Electron app without dragging the web UI along.
Tiny shared package for loading MediaPipe and onnxruntime-web, fetching the vocabulary, and the pure admitToken function used by the production mode controller.
The frozen LEAN_OPTIONS_SYSTEM prompt, the request builder that formats top-K tokens and dialog history, and the Zod-backed response parser.
OpenRouter HTTP client, ElevenLabs WSS streaming, the mode-controller finite state machine, the sign-classifier orchestration, and the Web Audio graph that publishes the signchat-voice track.
“LiveKit Cloud, OpenRouter, and ElevenLabs handle every per-turn data path. Vercel mints credentials — it’s not on the per-turn path.”
Numbers from the latest in-repo sweep (prompt-tester-service / RESULTS.md): 10 models × 399 scenarios = 3,990 OpenRouter calls. The numbers below are for the model call only — not the full sign-end → audible-byte path. Add ~300–500 ms for ElevenLabs TTS + audio mixing.
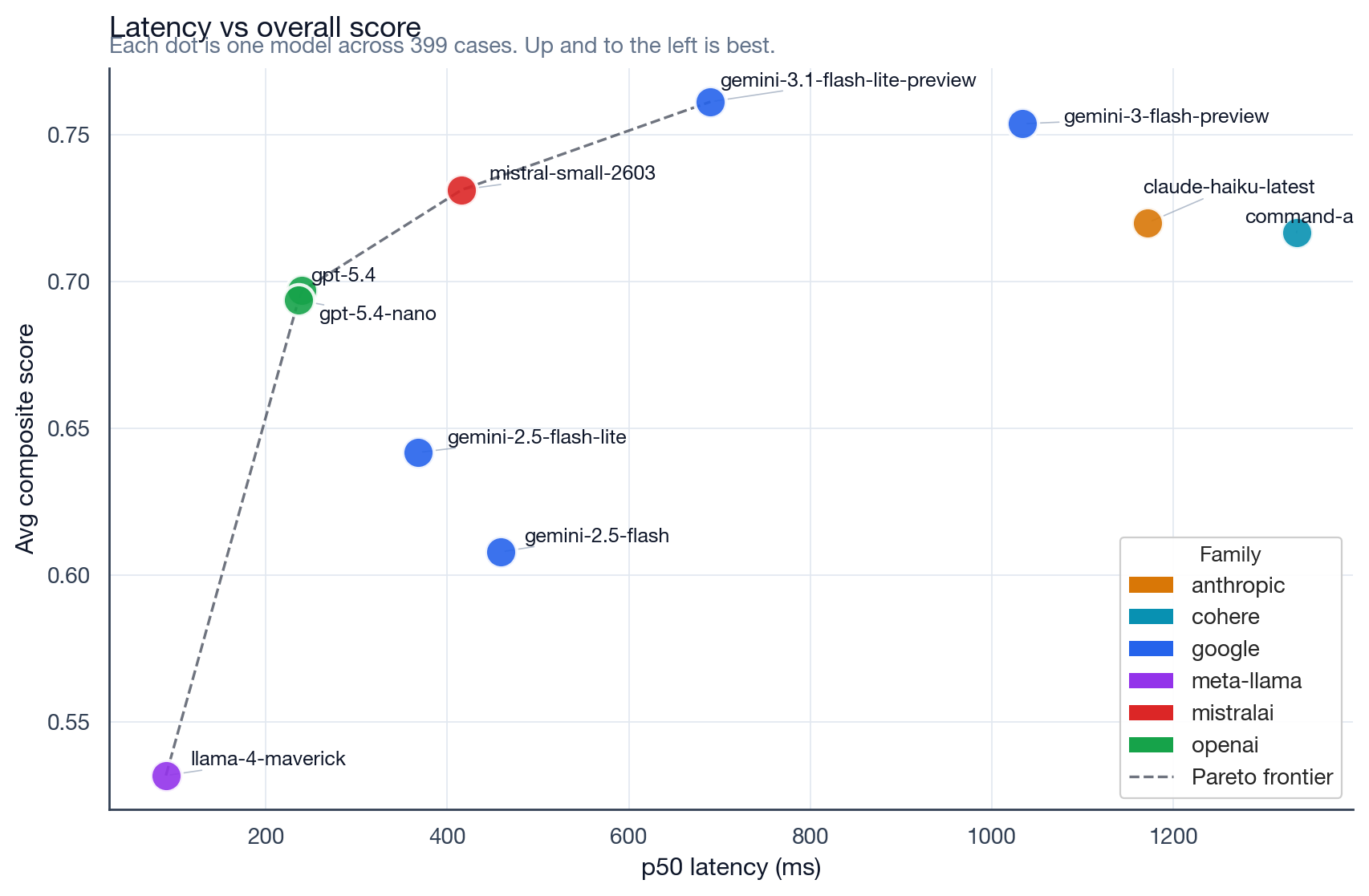
Each dot is one model across 399 cases. Up and to the left is best. Two models (claude-haiku-latest, command-a) have high timeout rates and are excluded from real-time use. Full methodology in the RESULTS.md.
Open a call and toggle the Debug pane to see classifier ticks, admitted tokens, OpenRouter latency, and TTS bytes in real time.
Open a callOr browse the packages →